
一、访问了一个已经被释放的对象
在不使用 ARC 的时候,内存要自己管理,这时重复或过早释放都有可能导致 Crash。
例子
NSObject * aObj = [[NSObject alloc] init];
[aObj release];
NSLog(@"%@", aObj);
原因
aObj 这个对象已经被释放,但是指针没有置空,这时访问这个指针指向的内存就会 Crash。
解决办法
- 使用前要判断非空,释放后要置空。正确的释放应该是:
[aObj release]; aObj = nil;由于ObjC的特性,调用 nil 指针的任何方法相当于无作用,所以即使有人在使用这个指针时没有判断至少还不会挂掉。
在ObjC里面,一切基于 NSObject 的对象都使用指针来进行调用,所以在无法保证该指针一定有值的情况下,要先判断指针非空再进行调用。
if (aObj) { //... }常见的如判断一个字符串是否为空:
if (aString && aString.length > 0) {//...} - 适当使用 autorelease。
有些时候不能知道自己创建的对象什么时候要进行释放,可以使用 autoRelease,但是不鼓励使用。因为 autoRelease 的对象要等到最近的一个 autoReleasePool 销毁的时候才会销毁,如果自己知道什么时候会用完这个对象,当然立即释放效率要更高。如果一定要用 autoRelease 来创建大量对象或者大数据对象,最好自己显式地创建一个 autoReleasePool,在使用后手动销毁。以前要自己手动初始化 autoReleasePool,现在可以用以下写法:
@autoreleasepool{ for (int i = 0; i < 100; ++i) { NSObject * aObj = [[[NSObject alloc] init] autorelease]; //.... } }
二、访问数组类对象越界或插入了空对象
NSMutableArray/NSMutableDictionary/NSMutableSet 等类下标越界,或者 insert 了一个 nil 对象。
原因
一个固定数组有一块连续内存,数组指针指向内存首地址,靠下标来计算元素地址,如果下标越界则指针偏移出这块内存,会访问到野数据,ObjC 为了安全就直接让程序 Crash 了。
而 nil 对象在数组类的 init 方法里面是表示数组的结束,所以使用 addObject 方法来插入对象就会使程序挂掉。如果实在要在数组里面加入一个空对象,那就使用 NSNull。
[array addObject:[NSNull null]];
解决办法
使用数组时注意判断下标是否越界,插入对象前先判断该对象是否为空。
if (aObj) {
[array addObject:aObj];
}
可以使用 Cocoa 的 Category 特性直接扩展 NSMutable 类的 Add/Insert 方法。比如:
@interface NSMutableArray (SafeInsert)
-(void) safeAddObject:(id)anObject;
@end
@implementation NSMutableArray (SafeInsert)
-(void) safeAddObject:(id)anObject {
if (anObject) {
[self addObject:anObject];
}
}
@end
这样,以后在工程里面使用 NSMutableArray 就可以直接使用 safeAddObject 方法来规避 Crash。
三、访问了不存在的方法
ObjC 的方法调用跟 C++ 很不一样。 C++ 在编译的时候就已经绑定了类和方法,一个类不可能调用一个不存在的方法,否则就报编译错误。而 ObjC 则是在 runtime 的时候才去查找应该调用哪一个方法。
这两种实现各有优劣,C++ 的绑定使得调用方法的时候速度很快,但是只能通过 virtual 关键字来实现有限的动态绑定。而对 ObjC 来说,事实上他的实现是一种消息传递而不是方法调用。
[aObj aMethod];
这样的语句应该理解为,像 aObj 对象发送一个叫做 aMethod 的消息,aObj 对象接收到这个消息之后,自己去查找是否能调用对应的方法,找不到则上父类找,再找不到就 Crash。由于 ObjC 的这种特性,使得其消息不单可以实现方法调用,还能紧系转发,对一个 obj 传递一个 selector 要求调用某方法,他可以直接不理会,转发给别的 obj 让别的 obj 来响应,非常灵活。
例子
[self methodNotExists];
调用一个不存在的方法,可以编译通过,运行时直接挂掉,报 NSInvalidArgumentException 异常:
-[WSMainViewController methodNotExist]: unrecognized selector sent to instance 0x1dd96160
2013-10-23 15:49:52.167 WSCrashSample[5578:907] *** Terminating app due to uncaught exception 'NSInvalidArgumentException', reason: '-[WSMainViewController methodNotExist]: unrecognized selector sent to instance 0x1dd96160'
解决方案
像这种类型的错误通常出现在使用 delegate 的时候,因为 delegate 通常是一个 id 泛型,所以 IDE 也不会报警告,所以这种时候要用 respondsToSelector 方法先判断一下,然后再进行调用。
if ([self respondsToSelector:@selector(methodNotExist)]) {
[self methodNotExist];
}
四、字节对齐
可能由于强制类型转换或者强制写内存等操作,CPU 执行 STMIA 指令时发现写入的内存地址不是自然边界,就会硬件报错挂掉。iPhone 5s 的 CPU 从32位变成64位,有可能会出现一些字节对齐的问题导致 Crash 率升高的。
例子
char *mem = malloc(16); // alloc 16 bytes of data
double *dbl = mem + 2;
double set = 10.0;
*dbl = set;
像上面这段代码,执行到
*dbl = set;
这句的时候,报了 EXC_BAD_ACCESS(code=EXC_ARM_DA_ALIGN) 错误。
原因
要了解字节对齐错误还需要一点点背景知识,知道的童鞋可以略过直接看后面了。
背景知识
计算机最小数据单位是bit(位),也就是0或1。
而内存空间最小单元是byte(字节),一个byte为8个bit。
内存地址空间以byte划分,所以理论上访问内存地址可以从任意byte开始,但是事实上我们不是直接访问硬件地址,而是通过操作系统的虚拟内存地址来访问,虚拟内存地址是以字为单位的。一个32位机器的字长就是32位,所以32位机器一次访问内存大小就是4个byte。再者为了性能考虑,数据结构(尤其是栈)应该尽可能地在自然边界上对齐。原因在于,为了访问未对齐的内存,处理器需要作两次内存访问;而对齐的内存访问仅需要一次访问。
举一个栗子:
struct foo {
char aChar1;
short aShort;
char aChar2;
int i;
};
上面这个结构体,在32位机器上,char 长度为8位,占一个byte,short 占2个byte, int 4个byte。
如果内存地址从 0 开始,那么理论上顺序分配的地址应该是:
aChar1 0x00000000
aShort 0x00000001
aChar2 0x00000003
i 0x00000004
但是事实上编译后,这些变量的地址是这样的:
aChar1 0x00000000
aShort 0x00000002
aChar2 0x00000004
i 0x00000008
这就是 aChar1 和 aChar2 都被做了内存对齐优化,都变成 2 byte 了。
解决办法
- 使用 memcpy 来作内存拷贝,而不是直接对指针赋值。对上面的例子作修改就是:
char *mem = malloc(16); // alloc 16 bytes of data double *dbl = mem + 2; double set = 10.0; memcpy(dbl, &set, sizeof(set));改用 memcpy 之后运行就不会有问题了,这是因为 memcpy 自己的实现就已经做了字节对齐的优化了。我们来看glibc2.5中的memcpy的源码:
void *memcpy (void *dstpp, const void *srcpp, size_t len) { unsigned long int dstp = (long int) dstpp; unsigned long int srcp = (long int) srcpp; if (len >= OP_T_THRES) { len -= (-dstp) % OPSIZ; BYTE_COPY_FWD (dstp, srcp, (-dstp) % OPSIZ); PAGE_COPY_FWD_MAYBE (dstp, srcp, len, len); WORD_COPY_FWD (dstp, srcp, len, len); } BYTE_COPY_FWD (dstp, srcp, len); return dstpp; }分析这个函数,首先比较一下需要拷贝的内存块大小,如果小于 OP_T_THRES (这里定义为 16),则直接字节拷贝就完了,如果大于这个值,视为大内存块拷贝,采用优化算法。
len -= (-dstp) % OPSIZ; BYTE_COPY_FWD (dstp, srcp, (-dstp) % OPSIZ); // #define OPSIZ (sizeof(op_t)) // enum op_tOPSIZE 是 op_t 的长度,op_t 是字的类型,所以这里 OPSIZE 是获取当前平台的字长。
dstp 是内存地址,内存地址是按byte来算的,对内存地址 unsigned long 取负数再模 OPSIZE 得到需要对齐的那部分数据的长度,然后用字节拷贝做内存对齐。取负数是因为要以dstp的地址作为起点来进行复制,如果直接取模那就变成0作为起点去做运算了。
对 BYTE_COPY_FWD 这个宏的源码有兴趣的同学可以看看这篇:BYTE_COPY_FWD 源码解析(感谢 @raincai 同学提醒)这样对齐了之后,再做大数据量部分的拷贝:
PAGE_COPY_FWD_MAYBE (dstp, srcp, len, len);看这个宏的源码,尽可能多地作页拷贝,剩下的大小会写入len变量。
///////////////////////////////////////////////// #if PAGE_COPY_THRESHOLD #include <assert.h> #define PAGE_COPY_FWD_MAYBE(dstp, srcp, nbytes_left, nbytes) \ do \ { \ if ((nbytes) >= PAGE_COPY_THRESHOLD && \ PAGE_OFFSET ((dstp) - (srcp)) == 0) \ { \ /* The amount to copy is past the threshold for copying \ pages virtually with kernel VM operations, and the \ source and destination addresses have the same alignment. */ \ size_t nbytes_before = PAGE_OFFSET (-(dstp)); \ if (nbytes_before != 0) \ { \ /* First copy the words before the first page boundary. */ \ WORD_COPY_FWD (dstp, srcp, nbytes_left, nbytes_before); \ assert (nbytes_left == 0); \ nbytes -= nbytes_before; \ } \ PAGE_COPY_FWD (dstp, srcp, nbytes_left, nbytes); \ } \ } while (0) /* The page size is always a power of two, so we can avoid modulo division. */ #define PAGE_OFFSET(n) ((n) & (PAGE_SIZE - 1)) #else #define PAGE_COPY_FWD_MAYBE(dstp, srcp, nbytes_left, nbytes) /* nada */ #endifPAGE_COPY_FWD 的宏定义:
#define PAGE_COPY_FWD ( dstp, srcp, nbytes_left, nbytes ) Value: ((nbytes_left) = ((nbytes) - \ (__vm_copy (__mach_task_self (), \ (vm_address_t) srcp, trunc_page (nbytes), \ (vm_address_t) dstp) == KERN_SUCCESS \ ? trunc_page (nbytes) \ : 0)))页拷贝剩余部分,再做一下字拷贝:
#define WORD_COPY_FWD ( dst_bp, src_bp, nbytes_left, nbytes ) Value: do \ { \ if (src_bp % OPSIZ == 0) \ _wordcopy_fwd_aligned (dst_bp, src_bp, (nbytes) / OPSIZ); \ else \ _wordcopy_fwd_dest_aligned (dst_bp, src_bp, (nbytes) / OPSIZ); \ src_bp += (nbytes) & -OPSIZ; \ dst_bp += (nbytes) & -OPSIZ; \ (nbytes_left) = (nbytes) % OPSIZ; \ } while (0)再再最后就是剩下的一点数据量了,直接字节拷贝结束。memcpy 可以用来解决内存对齐问题,同时对于大数据量的内存拷贝,使用 memcpy 效率要高很多,就因为做了页拷贝和字拷贝的优化。
- 或者尽量避免这种内存不对齐的情况,像这个例子,只要把 +2 改成 +4,内存就对齐了。当然具体还得看逻辑实现的需要。
char *mem = malloc(16); // alloc 16 bytes of data double *dbl = mem + 4; double set = 10.0; *dbl = set;
References
ARM Hacking: EXC_ARM_DA_ALIGN exception
五、堆栈溢出
一般情况下应用程序是不需要考虑堆和栈的大小的,总是当作足够大来使用就能满足一般业务开发。但是事实上堆和栈都不是无上限的,过多的递归会导致栈溢出,过多的 alloc 变量会导致堆溢出。
例子
不得不说 Cocoa 的内存管理优化做得挺好的,单纯用 C++ 在 Mac 下编译后执行以下代码,递归 174671 次后挂掉:
#include <iostream>
#include <stdlib.h>
void test(int i) {
void* ap = malloc(1024);
std::cout << ++i << "\n";
test(i);
}
int main() {
std::cout << "start!" << "\n";
test(0);
return 0;
}
而在 iOS 上执行以下代码则怎么也不会挂,连 memory warning 都没有:
- (void)stackOverFlow:(int)i {
char * aLeak = malloc(1024);
NSLog(@"try %d", ++i);
[self stackOverFlow:i];
}
而且如果 malloc 的大小改成比 1024 大的如 10240,其内存占用的增长要远慢于 1024。这大概要归功于 Cocoa 的 Flyweight 设计模式,不过暂时还没能真的理解到其优化原理,猜测可能是虽然内存空间申请了但是一直没用到,针对这种循环 alloc 的场景,做了记录,等到用到内存空间了才真正给出空间。
原理
iOS 内存布局如下图所示:
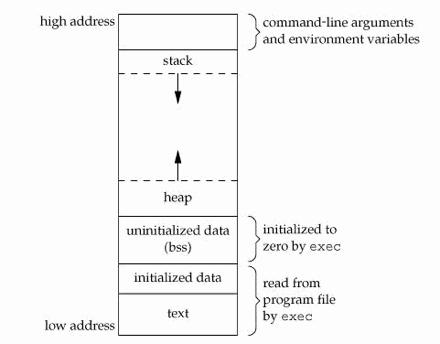
在应用程序分配的内存空间里面,最低地址位是固定的代码段和数据段,往上是堆,用来存放全局变量,对于 ObjC 来说,就是 alloc 出来的变量,都会放进这里,堆不够用的时候就会往上申请空间。最顶部高地址位是栈,局部的基本类型变量都会放进栈里。 ObjC 的对象都是以指针进行操控的,局部变量的指针都在栈里,全局的变量在堆里,而无论是什么指针,alloc 出来的都在堆里,所以 alloc 出来的变量一定要记得 release。
对于 autorelease 变量来说,每个函数有一个对应的 autorelease pool,函数出栈的时候 pool 被销毁,同时调用这个 pool 里面变量的 dealloc 函数来实现其内部 alloc 出来的变量的释放。
六、多线程并发操作
这个应该是全平台都会遇到的问题了。当某个对象会被多个线程修改的时候,有可能一个线程访问这个对象的时候另一个线程已经把它删掉了,导致 Crash。比较常见的是在网络任务队列里面,主线程往队列里面加入任务,网络线程同时进行删除操作导致挂掉。
例子
这个真要写比较完整的并发操作的例子就有点复杂了。
解决方法
- 加锁
- NSLock
普通的锁,加锁的时候 lock,解锁调用 unlock。
- (void)addPlayer:(Player *)player { if (player == nil) return; NSLock* aLock = [[NSLock alloc] init]; [aLock lock]; [players addObject:player]; [aLock unlock]; } }可以使用标记符 @synchronized 简化代码:
- (void)addPlayer:(Player *)player { if (player == nil) return; @synchronized(players) { [players addObject:player]; } } - NSRecursiveLock 递归锁
使用普通的 NSLock 如果在递归的情况下或者重复加锁的情况下,自己跟自己抢资源导致死锁。Cocoa 提供了 NSRecursiveLock 锁可以多次加锁而不会死锁,只要 unlock 次数跟 lock 次数一样就行了。
- NSConditionLock 条件锁
多数情况下锁是不需要关心什么条件下 unlock 的,要用的时候锁上,用完了就 unlock 就完了。Cocoa 提供这种条件锁,可以在满足某种条件下才解锁。这个锁的 lock 和 unlock, lockWhenCondition 是随意组合的,可以不用对应起来。
- NSDistributedLock 分布式锁
这是用在多进程之间共享资源的锁,对 iOS 来说暂时没用处。
- NSLock
-
无锁
放弃加锁,采用原子操作,编写无锁队列解决多线程同步的问题。酷壳有篇介绍无锁队列的文章可以参考一下:无锁队列的实现 - 使用其他备选方案代替多线程:Operation Objects, GCD, Idle-time notifications, Asynchronous functions, Timers, Separate processes。
References
七、Repeating NSTimer
如果一个 Timer 是不停 repeat,那么释放之前就应该先 invalidate。非repeat的timer在fired的时候会自动调用invalidate,但是repeat的不会。这时如果释放了timer,而timer其实还会回调,回调的时候找不到对象就会挂掉。
原因
NSTimer 是通过 RunLoop 来实现定时调用的,当你创建一个 Timer 的时候,RunLoop 会持有这个 Timer 的强引用,如果你创建了一个 repeating timer,在下一次回调前就把这个 timer release了,那么 runloop 回调的时候就会找不到对象而 Crash。
解决方案
我写了个宏用来释放Timer
/*
* 判断这个Timer不为nil则停止并释放
* 如果不先停止可能会导致crash
*/
#define WVSAFA_DELETE_TIMER(timer) { \
if (timer != nil) { \
[timer invalidate]; \
[timer release]; \
timer = nil; \
} \
}